# Installation
Each of the base services needs to be run separately on different ports. These ports are already configured and can be found in usage section. Once they are up and running requests can be made to any of these services. See the usage section to see which parameters are to be send in addition to the request. In the section below you can see the outputs for each of the base services.
# Pre-Processing
The pre-processing base service has multiple api for different processing techniques. The image below shows the data returned by this base services for the api calls to remove nan (/nan), statistical info (/info), standardize the data (/std) and to remove highly corelated features (/rm_corr) respectively.
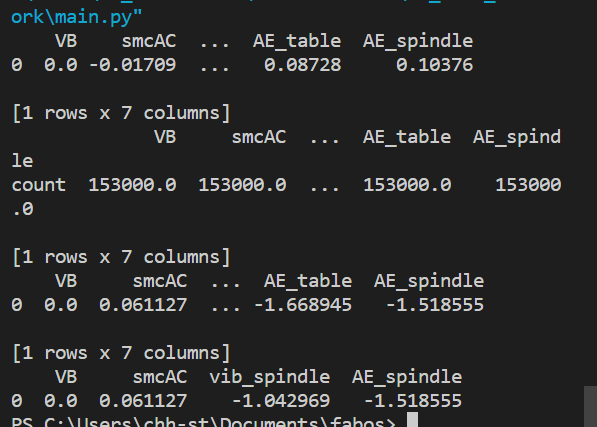
All of them return dataframe except for info which returns the statistical info like count, mean, etc. of each column. The output above only prints the first row of each dataframe received.
# AI-ToolBox
This is the service where the AI model is created, trained and stored. While making the call to this service make sure to mention whether it is a regression problem or classification problem. Once the request is sent the creation and training of model will start at the api backend.
Once the model is trained the sends back the message 'Done' a sshown in the figure below.
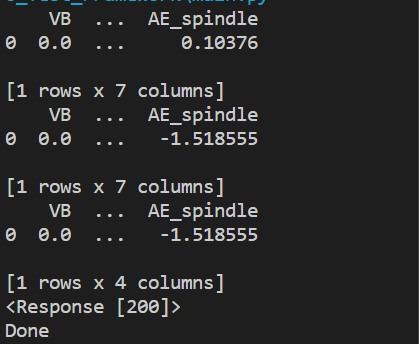
The model itself is stored under the Models folder, but the model is stored as an folder and not as a file which makes it difficult to transfer during api calls. Thus, a zipped version of the model is also created which can be transferred in between base services for evaluation or other processes.
# Evaluation
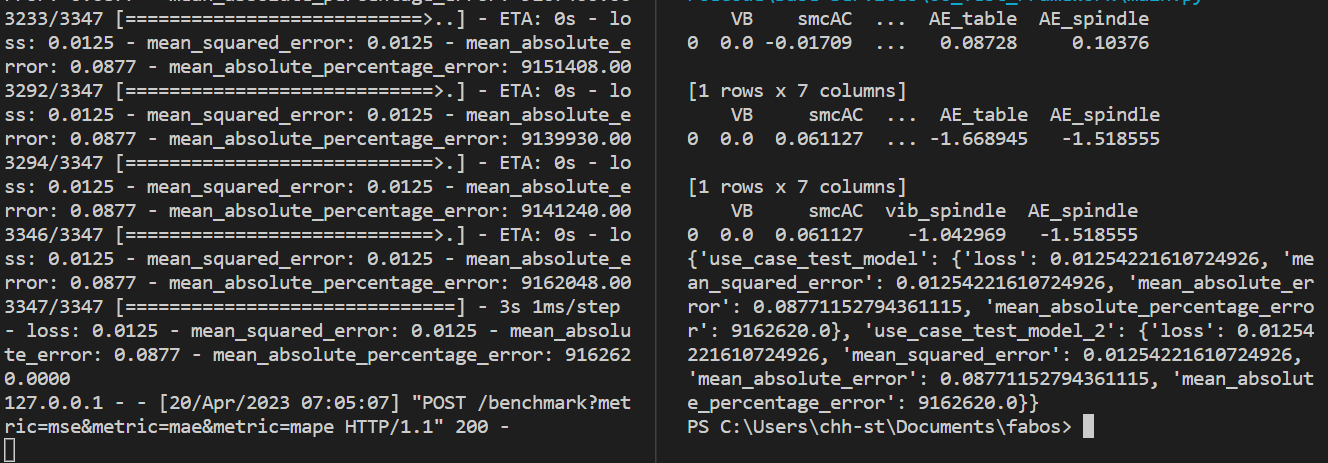
This is the base service where the model is evaluated on the testing data to check for model accuracy and loss. It has two Api calls: evaluate and benchmark. Evaluate performs evaluation for only one model and returns the evaluation results.
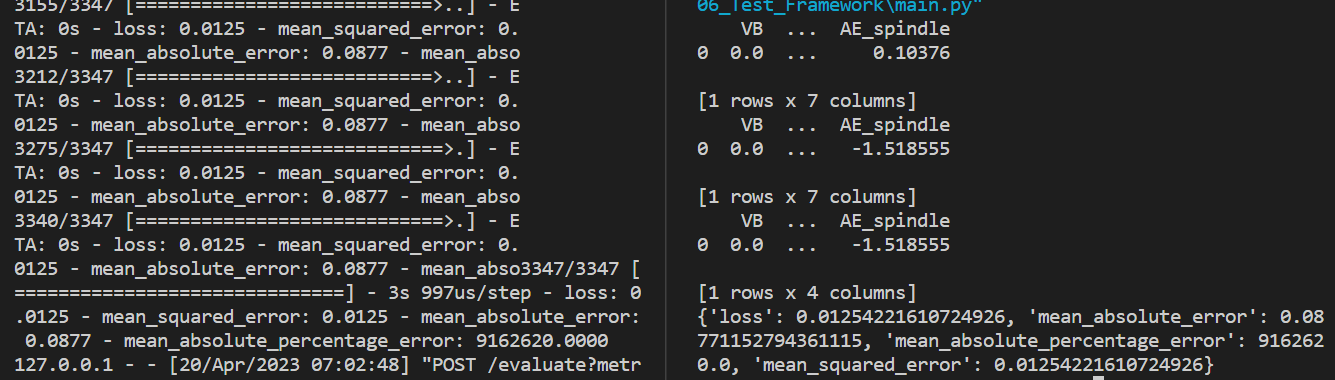
Benchmark performs evaluation for multiple models on the same dataset to compare them and returns the evaluation results for all models in a single dictionary.